9.10 Event study model
As we have discussed, the validity of DiD estimate depends on the parallel trend assumption. Since the direct test for parallel trend requires the potential outcome of treated unit in absence of the treatment, it is not feasible. Although we are not going to be able to directly test the parallel trend, we can provide suggestive evidence in favor of (or lack of) parallel trend. For this, we need multi-period data, particularly for periods prior to the implementation of the treatment.
A simple way to assess parallel trend is to evaluate the unconditional means across the treated and untreated units (expansion and non-expansion states in our case). This is shown in Section 4 (DiD in multi-period set up). I’ve included the figure here.
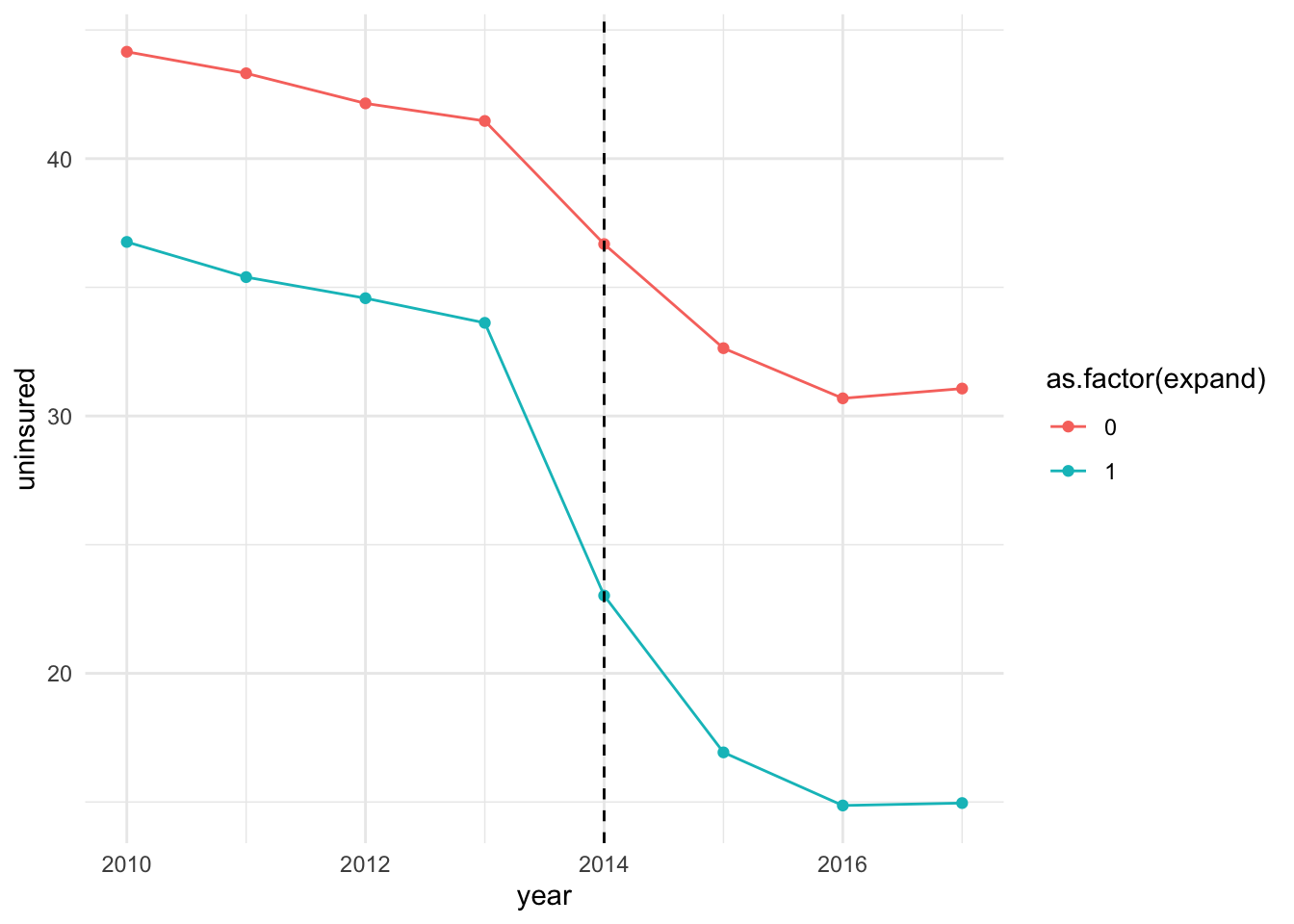
Here, we see that the uninsured rates between the expansion and non-expansion states trended similarly (or parallely) prior to the treatment. This allows us to argue that trends in uninsured rate would’ve remained similar (or would not differ systematically) in absence of the ACA-Medicaid reform. This by far is the simplest but yet powerful way to argue parallel trend assumption in practice. However, note that units in non-expansion states on average had higher uninsured rate compared to their counterparts in the expansion states even prior to the reform. Ideally, we would want treated and control units to have similar baseline features. This is where regression comes into play. Using regression, we can evaulate a difference-in-differences model by accounting for necessary covariates.9 Moreover, it allows us to evaluate dynamic effects of the treatment, i.e., the impacts of the treatment over time (1st period, 2nd period, and so on).
The event study model can be written as:
\[\begin{equation} \label{eq:DiD_eventstudy} Y_{it} = \alpha + \underbrace{\sum_{j = -k}^{k}}_{j \neq -1} \tau_j \times 1(\underbrace{t - G}_{r} = j) \times D_i + \sigma_{t} + \eta D_{i} + \epsilon_{it} \end{equation}\]
So what are these notations here?
\(\alpha\) is the intercept
\(1(\underbrace{t - G}_{r} = j)\): This is an indicator that turns on (takes the value 1) when the relative time \(r\) in the data is equal to \(j\), and turns off otherwise (takes the value 0). The relative time, \(r\), is simply the difference between the period \(t\) and the implementation year of the reform \(E\). For simplicity, I have the minimum and maximum of relative time as \(-k\) and \(k\), respectively. But of course, this can vary in practice. The omitted category is the year before the reform (i.e., when \(r = -1\)). We’ll discuss more about the omitted category later on.
\(\sigma_t\): Is the time fixed effects. It captures the changes that are common across treatment and control units over time.
\(D_i\): Is the fixed effects for treated/control units. In practice, treatment and control units can fundamentally differ in several characteristics. Accounting for \(D_i\) separately captures the average difference in the outcome between treatment and control units that does not change over time (time invariant). In other words, controling for \(D_i\) accounts for time invariant heterogeneity across the treatment vs. control groups. For example, we saw that expansion units on average had lower uninsured rate even prior to the reform compared to the treated units. For instance, this aspect of the difference in outcomes across the two groups is accounted by \(D_i\).
From a specification perspectice, the main difference between the canonical DiD specification and the event study specification is the incorporation of the term \(1(\underbrace{t - G}_{r} = j)\), which is interacted with the treatment indicator, \(D_i\). This allows us to evaluate the effect of the treatment separately for a given period following (or before) the treatment implementation. Such dynamic effects are picked up by \(\widehat{\tau_t}\).
Let’s try and break down whats going on in the event study specification.
First, it is important to realize the role of the omitted category. In the event study specification above, I’ve dropped the period prior to the reform. Note that this is essential from a theroretical standpoint, since inclusion of all periods would result to a fully saturated model and create multicollinearity.
Dropping the period prior to the treatment implementation uses this period as the relative period.
From point 2, we can think of the event-study specification as estimating several DiD type models, where the second difference is fixed and pertains to the omitted period, while the period of interest varies. Let me elaborate on this.
To see this, note that when \(t - G = -1\), the conditional expectation for the treated group is \(E(Y | D = 1, t = G - 1) = \alpha + \sigma_{(G-1)} + \eta\) and and for the control group is: \(E(Y | D = 0, G-1) = \alpha + \sigma_{(G-1)}\).
\(E(Y | D = 1, G - 1) - E(Y | D = 0, G-1)\) is synonymous to the second difference: i.e., the difference in conditional means between the treatment and control units in the period before the treatment implementation. For the first difference, let’s look at the relative period \(t - G = 0\), the period of the reform implementation. The conditional expectation for the treatment group is: \(E(Y | D = 1, t = G) = \alpha + \tau_0 + \sigma_{G} + \eta\) and that for the control group is: \(E(Y | D = 0, t = G) = \alpha + \sigma_{G}\). Here, the first difference is: \(E(Y | D = 1, t = G) - E(Y | D = 0, t = G)\).
The DiD estimand during the period of the reform, \(r=0\), is given as:
\[\begin{equation} \underbrace{E(Y | D = 1, t = G) - E(Y | D = 0, t = G)}_{first\; difference} - \underbrace{E(Y | D = 1, t = G - 1) - E(Y | D = 0, t = G-1)}_{second\; difference} = \tau_0 \end{equation}\]
The DiD estimand for the period following the reform \((r= 1)\) is given as:
\[\begin{equation} \underbrace{E(Y | D = 1, t = G+1) - E(Y | D = 0, t = G+1)}_{first\; difference} - \underbrace{E(Y | D = 1, t = G - 1) - E(Y | D = 0, t = G-1)}_{second\; difference} = \tau_1 \end{equation}\]
Similarly, we can think of the event study model as nesting the DiD estimation pertaining to the relative periods, \(r=2, \; 3\) and so on.
This way, the event study specification allows us to estimate period specific treatment effects from relative time period \(-k\) to \(k\) in relation to the conditional mean difference between the treated and control groups a period prior to the treatment implementation. Following the estimation of the event study model, we will have two sets of estimates: i) \(\tau_{-k}, \; \tau_{-k+1}, ..., \; \tau_{-2}\), and ii) \(\tau_{1}\), \(\tau_{2}\), …, \(\tau_{k}\). The estimation of \(\tau\)s prior to the treatment allows us to make inference regarding the parallel trend assumption. If \(\widehat{\tau}_j\) for \(j<-1\) is close to zero, then it provides suggestive evidence that the outcomes between the treatment and control units are trending similarly prior to the treatment.
Let’s estimate the event study model for the ACA-Medicaid data. Note that we are using the larger data set where year spans from 2010 to 2018.
- First create the relative time variable.
mort_allcauses <- mort_allcauses %>%
mutate(yeararound = year - yearexpand)
# view
table(mort_allcauses$yeararound)##
## -4 -3 -2 -1 0 1 2 3
## 2614 2617 2619 2620 2608 2616 2615 2615- Note that the relative time spans from -4 to 3. Since, we are only considering the states that implemented ACA-Medicaid expansion in year 2014, -4 pertains to year 2010, -3 to 2011, and so on. Next, let’s create relative time indicators and interact them with the expansion status. In the model, this pertains to \(1(\underbrace{t - G}_{r} = j) \times D_i\) part.
mort_allcauses <- mort_allcauses %>%
mutate(rel_pre4 = ifelse(yeararound == -4, 1, 0), # indicator for r = -4
rel_pre4 = rel_pre4 * expand, # interact the indicator for r = -4 with expansion status
rel_pre3 = ifelse(yeararound == -3, 1, 0),
rel_pre3 = rel_pre3 * expand,
rel_pre2 = ifelse(yeararound == -2, 1, 0),
rel_pre2 = rel_pre2 * expand,
rel_pre1 = ifelse(yeararound == -1, 1, 0),
rel_pre1 = rel_pre1 * expand,
rel_post0 = ifelse(yeararound == 0, 1, 0),
rel_post0 = rel_post0 * expand,
rel_post1 = ifelse(yeararound == 1, 1, 0),
rel_post1 = rel_post1 * expand,
rel_post2 = ifelse(yeararound == 2, 1, 0),
rel_post2 = rel_post2 * expand,
rel_post3 = ifelse(yeararound == 3, 1, 0),
rel_post3 = rel_post3 * expand)- Now thats done, let’s specify the model and estimate it using OLS.
## # A tibble: 6 × 16
## countyfips year state.abb expand yearexpand sahieunins138 GovernorisDemocrat1Yes yeararound rel_pre4 rel_pre3 rel_pre2 rel_pre1 rel_post0 rel_post1
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 2010 AL 0 2014 40.6 0 -4 0 0 0 0 0 0
## 2 1001 2011 AL 0 2014 41.6 0 -3 0 0 0 0 0 0
## 3 1001 2012 AL 0 2014 39.6 0 -2 0 0 0 0 0 0
## 4 1001 2013 AL 0 2014 39.6 0 -1 0 0 0 0 0 0
## 5 1001 2014 AL 0 2014 31.9 0 0 0 0 0 0 0 0
## 6 1001 2015 AL 0 2014 27.5 0 1 0 0 0 0 0 0
## # ℹ 2 more variables: rel_post2 <dbl>, rel_post3 <dbl># specify the event study model
reg_es <- lm(sahieunins138 ~ rel_pre4 + rel_pre3 + rel_pre2 +
rel_post0 + rel_post1 + rel_post2 + rel_post3 +
factor(state.abb) +
factor(year),
data = mort_allcauses
)
# print summary of the results
summary(reg_es)##
## Call:
## lm(formula = sahieunins138 ~ rel_pre4 + rel_pre3 + rel_pre2 +
## rel_post0 + rel_post1 + rel_post2 + rel_post3 + factor(state.abb) +
## factor(year), data = mort_allcauses)
##
## Residuals:
## Min 1Q Median 3Q Max
## -22.0650 -3.2383 -0.3658 2.7562 22.4298
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 41.4230 0.2496 165.952 < 2e-16 ***
## rel_pre4 0.4025 0.2740 1.469 0.141786
## rel_pre3 -0.1852 0.2739 -0.676 0.499059
## rel_pre2 0.1952 0.2738 0.713 0.475988
## rel_post0 -5.7906 0.2742 -21.115 < 2e-16 ***
## rel_post1 -7.8759 0.2739 -28.757 < 2e-16 ***
## rel_post2 -7.9523 0.2739 -29.032 < 2e-16 ***
## rel_post3 -8.2633 0.2739 -30.165 < 2e-16 ***
## factor(state.abb)AR 2.3846 0.3504 6.806 1.03e-11 ***
## factor(state.abb)AZ -0.6241 0.5306 -1.176 0.239519
## factor(state.abb)CA -2.3065 0.3669 -6.286 3.32e-10 ***
## factor(state.abb)CO -0.2576 0.3711 -0.694 0.487555
## factor(state.abb)CT -10.4509 0.7144 -14.629 < 2e-16 ***
## factor(state.abb)DE -9.1957 1.0411 -8.833 < 2e-16 ***
## factor(state.abb)FL 4.2887 0.3050 14.060 < 2e-16 ***
## factor(state.abb)GA 6.7838 0.2625 25.846 < 2e-16 ***
## factor(state.abb)IA -8.9609 0.3341 -26.822 < 2e-16 ***
## factor(state.abb)ID 4.5479 0.3467 13.117 < 2e-16 ***
## factor(state.abb)IL -7.3991 0.3341 -22.147 < 2e-16 ***
## factor(state.abb)KS -1.1298 0.2852 -3.961 7.48e-05 ***
## factor(state.abb)KY -3.5130 0.3256 -10.791 < 2e-16 ***
## factor(state.abb)MA -21.4058 0.5439 -39.357 < 2e-16 ***
## factor(state.abb)MD -7.6416 0.4542 -16.825 < 2e-16 ***
## factor(state.abb)ME -9.4409 0.4860 -19.426 < 2e-16 ***
## factor(state.abb)MI -6.1339 0.3429 -17.886 < 2e-16 ***
## factor(state.abb)MN -13.0886 0.3416 -38.316 < 2e-16 ***
## factor(state.abb)MO -0.6158 0.2726 -2.259 0.023884 *
## factor(state.abb)MS 4.2729 0.2975 14.361 < 2e-16 ***
## factor(state.abb)NC 3.2062 0.2802 11.441 < 2e-16 ***
## factor(state.abb)ND -3.4350 0.3977 -8.637 < 2e-16 ***
## factor(state.abb)NE -3.6131 0.3004 -12.029 < 2e-16 ***
## factor(state.abb)NH -3.3591 0.6179 -5.436 5.50e-08 ***
## factor(state.abb)NJ 1.6554 0.4819 3.435 0.000594 ***
## factor(state.abb)NM 5.0624 0.4486 11.284 < 2e-16 ***
## factor(state.abb)NV 7.6758 0.5513 13.922 < 2e-16 ***
## factor(state.abb)NY -10.9051 0.3598 -30.310 < 2e-16 ***
## factor(state.abb)OH -5.6530 0.3398 -16.634 < 2e-16 ***
## factor(state.abb)OK 7.4075 0.2976 24.887 < 2e-16 ***
## factor(state.abb)OR -1.8950 0.4148 -4.568 4.95e-06 ***
## factor(state.abb)RI -7.5116 0.8262 -9.091 < 2e-16 ***
## factor(state.abb)SC 1.6600 0.3413 4.863 1.16e-06 ***
## factor(state.abb)SD -0.9894 0.3298 -3.000 0.002703 **
## factor(state.abb)TN -2.3999 0.2825 -8.495 < 2e-16 ***
## factor(state.abb)TX 13.7492 0.2509 54.804 < 2e-16 ***
## factor(state.abb)UT -0.3493 0.3995 -0.875 0.381846
## factor(state.abb)VA -1.2731 0.2690 -4.733 2.23e-06 ***
## factor(state.abb)VT -16.4906 0.5589 -29.506 < 2e-16 ***
## factor(state.abb)WA -1.6794 0.4056 -4.141 3.47e-05 ***
## factor(state.abb)WI -12.2690 0.3039 -40.366 < 2e-16 ***
## factor(state.abb)WV -2.8616 0.3683 -7.770 8.18e-15 ***
## factor(state.abb)WY 2.8195 0.4239 6.652 2.97e-11 ***
## factor(year)2011 -0.7485 0.1797 -4.166 3.11e-05 ***
## factor(year)2012 -2.0058 0.1797 -11.163 < 2e-16 ***
## factor(year)2013 -2.7830 0.1796 -15.493 < 2e-16 ***
## factor(year)2014 -7.5810 0.1797 -42.191 < 2e-16 ***
## factor(year)2015 -11.5876 0.1798 -64.456 < 2e-16 ***
## factor(year)2016 -13.5230 0.1798 -75.222 < 2e-16 ***
## factor(year)2017 -13.1527 0.1797 -73.187 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.906 on 20866 degrees of freedom
## Multiple R-squared: 0.8301, Adjusted R-squared: 0.8296
## F-statistic: 1788 on 57 and 20866 DF, p-value: < 2.2e-16- Let’s cluster the standard error at the state level. I’m going to do this using feols command from fixest package. Using feols you can automatically create the relative time indicators and interact them with the treatment status as in the coding below.
reg_es_cluster <- feols(sahieunins138 ~ i(yeararound, expand, ref = -1) | year + state.abb,
data = mort_allcauses, cluster = ~state.abb
)
summary(reg_es_cluster)## OLS estimation, Dep. Var.: sahieunins138
## Observations: 20,924
## Fixed-effects: year: 8, state.abb: 44
## Standard-errors: Clustered (state.abb)
## Estimate Std. Error t value Pr(>|t|)
## yeararound::-4:expand 0.402513 0.510512 0.788449 4.3476e-01
## yeararound::-3:expand -0.185154 0.381186 -0.485731 6.2962e-01
## yeararound::-2:expand 0.195173 0.320074 0.609773 5.4522e-01
## yeararound::0:expand -5.790635 1.324081 -4.373323 7.6407e-05 ***
## yeararound::1:expand -7.875889 1.466538 -5.370394 2.9855e-06 ***
## yeararound::2:expand -7.952329 1.469702 -5.410843 2.6106e-06 ***
## yeararound::3:expand -8.263343 1.506539 -5.484985 2.0408e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## RMSE: 4.89924 Adj. R2: 0.829592
## Within R2: 0.131658We see that the relative time estimates from 3 and 2 are equal to one another. However, the clustered standard errors are inflated.
- We can then plot the event study estimates.
# Extract coefficients and confidence intervals
event_study_results <- fixest::coefplot(reg_es_cluster, main = "Event Study Estimates")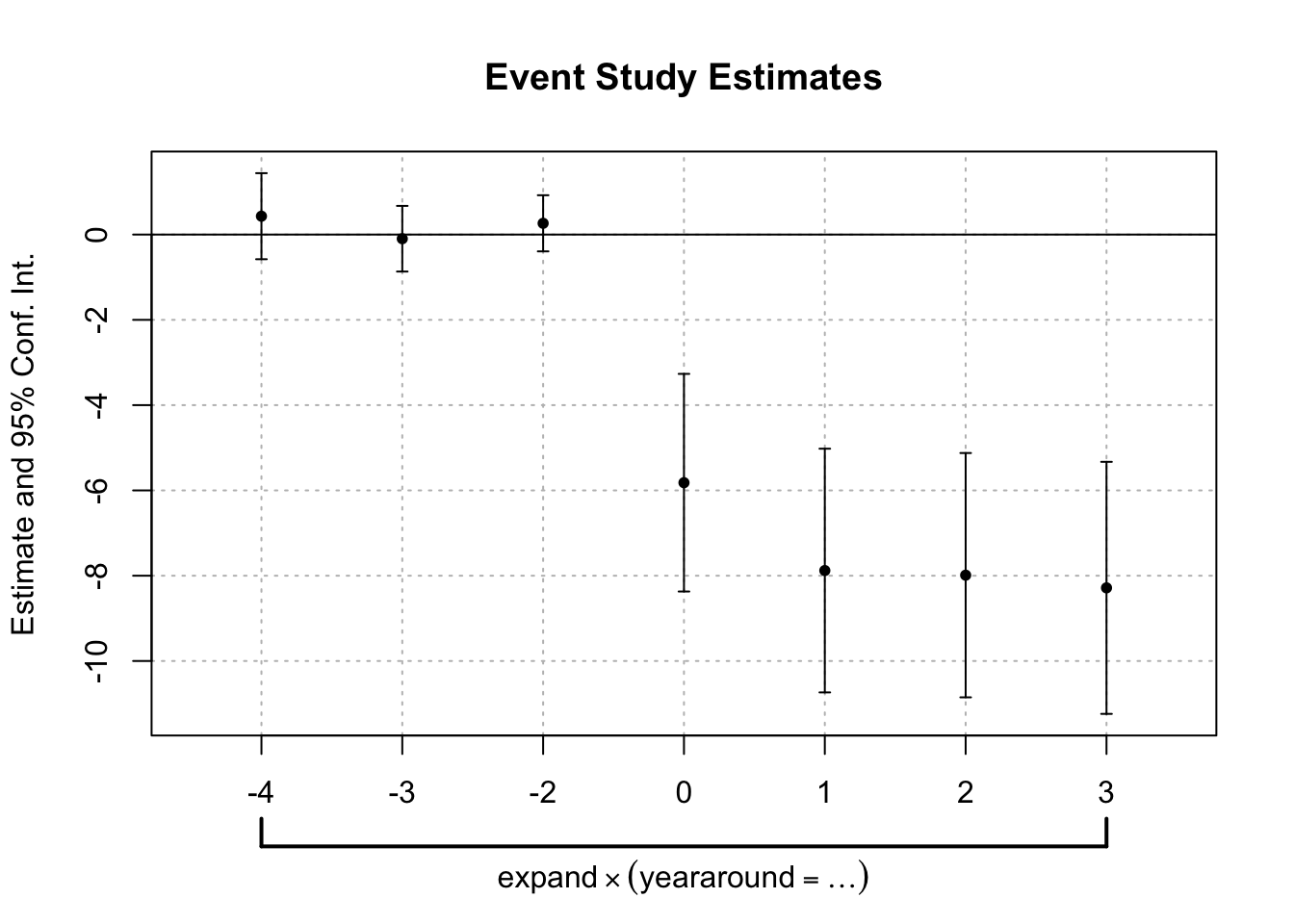
## estimate ci_low ci_high estimate_names estimate_names_raw id x y
## yeararound::-4:expand 0.4025128 -0.6270325 1.4320580 yeararound::-4:expand yeararound::-4:expand 1 1 0.4025128
## yeararound::-3:expand -0.1851537 -0.9538886 0.5835811 yeararound::-3:expand yeararound::-3:expand 1 2 -0.1851537
## yeararound::-2:expand 0.1951727 -0.4503186 0.8406640 yeararound::-2:expand yeararound::-2:expand 1 3 0.1951727
## yeararound::0:expand -5.7906348 -8.4608988 -3.1203708 yeararound::0:expand yeararound::0:expand 1 4 -5.7906348
## yeararound::1:expand -7.8758890 -10.8334453 -4.9183327 yeararound::1:expand yeararound::1:expand 1 5 -7.8758890
## yeararound::2:expand -7.9523287 -10.9162658 -4.9883916 yeararound::2:expand yeararound::2:expand 1 6 -7.9523287
## yeararound::3:expand -8.2633434 -11.3015687 -5.2251181 yeararound::3:expand yeararound::3:expand 1 7 -8.2633434We see that the estimates on \(\tau_j\) for \(j<-1\) is close to zero and statistically insignificant at the conventional levels. This provides a suggestive evidence in favor of the parallel trend assumption. However, the estimates following the reform implementation drops drastically, demonstrating the reduction in uninsured rate due to the ACA-Medicaid expansion.
Again what is necessary is a subject to debate, which we will stay away from for now.↩︎